
A shapeshifting robotic microswarm may one day act as a toothbrush, rinse, and dental floss in one.
The technology, developed by a multidisciplinary team at the University of Pennsylvania, is poised to offer a new and automated way to perform the mundane but critical daily tasks of brushing and flossing. It’s a system that could be particularly valuable for those who lack the manual dexterity to clean their teeth effectively themselves.
The building blocks of these microrobots are iron oxide nanoparticles that have both catalytic and magnetic activity. Using a magnetic field, researchers could direct their motion and configuration to form either bristlelike structures that sweep away dental plaque from the broad surfaces of teeth, or elongated strings that can slip between teeth like a length of floss. In both instances, a catalytic reaction drives the nanoparticles to produce antimicrobials that kill harmful oral bacteria on site.
Experiments using this system on mock and real human teeth showed that the robotic assemblies can conform to a variety of shapes to nearly eliminate the sticky biofilms that lead to cavities and gum disease. The Penn team shared their findings establishing a proof-of-concept for the robotic system in the journal ACS Nano.
“Routine oral care is cumbersome and can pose challenges for many people, especially those who have hard time cleaning their teeth” says Hyun (Michel) Koo, a professor in the Department of Orthodontics and divisions of Community Oral Health and Pediatric Dentistry in Penn’s School of Dental Medicine and co-corresponding author on the study. “You have to brush your teeth, then floss your teeth, then rinse your mouth; it’s a manual, multistep process. The big innovation here is that the robotics system can do all three in a single, hands-free, automated way.”
“Nanoparticles can be shaped and controlled with magnetic fields in surprising ways,” says Edward Steager, a senior research investigator in Penn’s School of Engineering and Applied Science and co-corresponding author. “We form bristles that can extend, sweep, and even transfer back and forth across a space, much like flossing. The way it works is similar to how a robotic arm might reach out and clean a surface. The system can be programmed to do the nanoparticle assembly and motion control automatically.”
Disrupting oral care technology
“The design of the toothbrush has remained relatively unchanged for millennia,” says Koo.
While adding electric motors elevated the basic “bristle-on-a-stick” format, the fundamental concept has remained the same. “It’s a technology that has not been disrupted in decades.”
Several years ago, Penn researchers within the Center for Innovation & Precision Dentistry (CiPD), of which Koo is a co-director, took steps toward a major disruption, using this microrobotics system.
Their innovation arose from a bit of serendipity. Research groups in both Penn Dental Medicine and Penn Engineering were interested in iron oxide nanoparticles but for very different reasons. Koo’s group was intrigued by the catalytic activity of the nanoparticles. They can activate hydrogen peroxide to release free radicals that can kill tooth decay-causing bacteria and degrade dental plaque biofilms. Meanwhile Steager and engineering colleagues, including Dean Vijay Kumar and Professor Kathleen Stebe, co-director of CiPD, were exploring these nanoparticles as building blocks of magnetically controlled microrobots.
With support from Penn Health Tech and the National Institutes of Health’s National Institute of Dental and Craniofacial Research, the Penn collaborators married the two applications in the current work, constructing a platform to electromagnetically control the microrobots, enabling them to adopt different configurations and release antimicrobials on site to effectively treat and clean teeth.
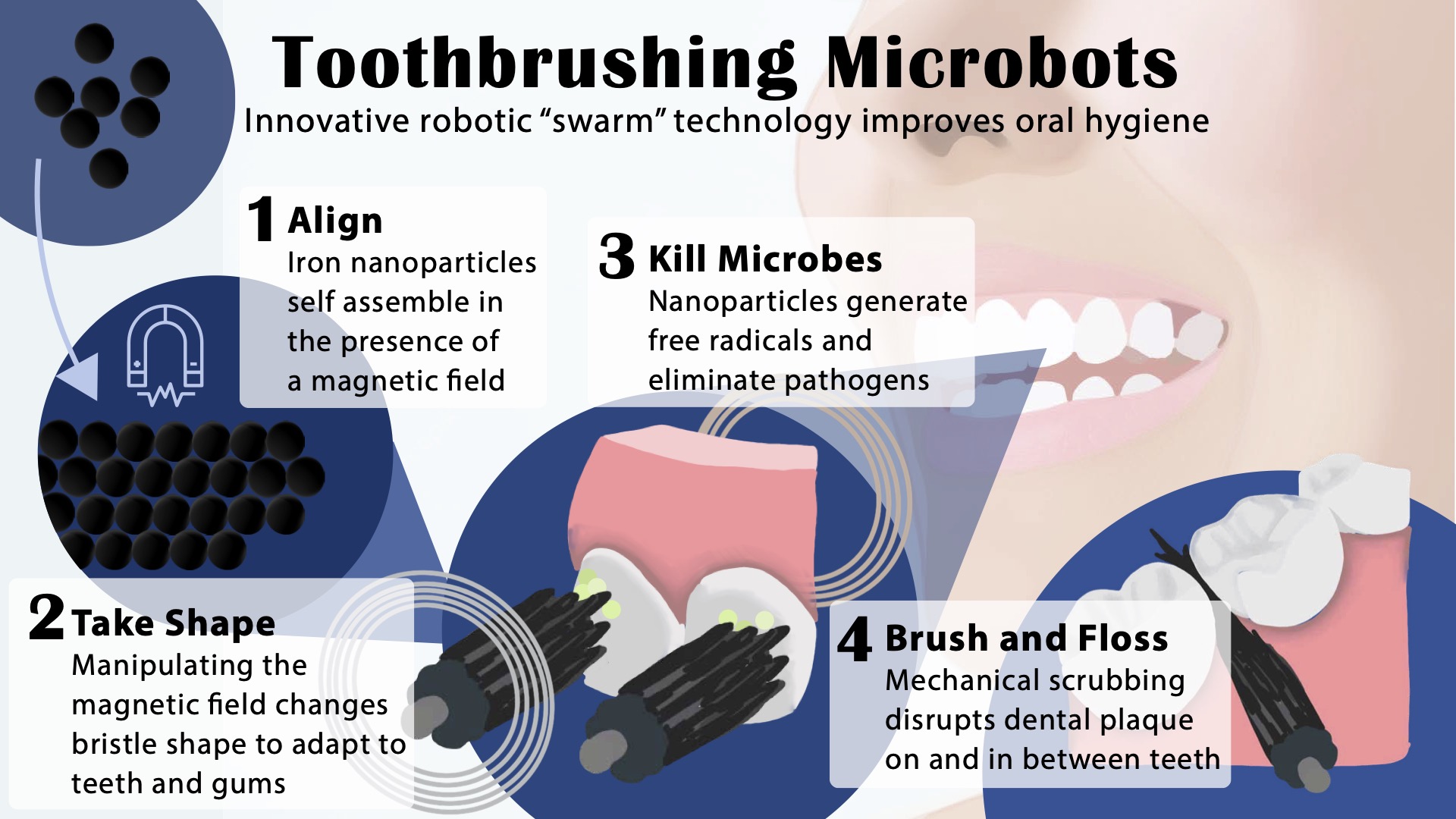
“It doesn’t matter if you have straight teeth or misaligned teeth, it will adapt to different surfaces,” says Koo. “The system can adjust to all the nooks and crannies in the oral cavity.”
The researchers optimized the motions of the microrobots on a small slab of toothlike material. Next, they tested the microrobots’ performance adjusting to the complex topography of the tooth surface, interdental surfaces, and the gumline, using 3D-printed tooth models based on scans of human teeth from the dental clinic. Finally, they trialed the microrobots on real human teeth that were mounted in such a way as to mimic the position of teeth in the oral cavity.
On these various surfaces, the researchers found that the microrobotics system could effectively eliminate biofilms, clearing them of all detectable pathogens. The iron oxide nanoparticles have been FDA approved for other uses, and tests of the bristle formations on an animal model showed that they did not harm the gum tissue.
Indeed, the system is fully programmable; the team’s roboticists and engineers used variations in the magnetic field to precisely tune the motions of the microrobots as well as control bristle stiffness and length. The researchers found that the tips of the bristles could be made firm enough to remove biofilms but soft enough to avoid damage to the gums.
The customizable nature of the system, the researchers say, could make it gentle enough for clinical use, but also personalized, able to adapt to the unique topographies of a patient’s oral cavity.
To advance this innovation to the clinic, the Penn team is continuing to optimize the robots’ motions and considering different means of delivering the microrobots through mouth-fitting devices.
They’re eager to see their device help people in the clinic.
“We have this technology that’s as or more effective as brushing and flossing your teeth but doesn’t require manual dexterity,” says Koo. “We’d love to see this helping the geriatric population and people with disabilities. We believe it will disrupt current modalities and majorly advance oral health care.”
Hyun (Michel) Koo is a professor in the Department of Orthodontics and divisions of Community Oral Health and Pediatric Dentistry in the School of Dental Medicine and co-director of the Center for Innovation & Precision Dentistry at the University of Pennsylvania.
Edward Steager is a senior research investigator in Penn’s School of Engineering and Applied Science.
Koo and Steager’s coauthors on the paper are Penn Dental Medicine’s Min Jun Oh, Alaa Babeer, Yuan Liu, and Zhi Ren and Penn Engineering’s Jingyu Wu, David A. Issadore, Kathleen J. Stebe, and Daeyeon Lee.
This work was supported in part by the National Institute for Dental and Craniofacial Research (grants DE025848 and DE029985), Procter & Gamble, and the Postdoctoral Research Program of Sungkyunkwan University.













{kind=link}